Here are some notes that I gathered while attending Kubecon NA 2021 Virtual (it was also happening in person in Los Angeles).
Approximately half of the sessions were pre recorded with speakers available in the chat and live at the end of the session; the other half being streamed live from LA.
Keynotes
CNCF and Kubernetes Updates
Linux is 30 years old!
A new foundation just got created by the Linux Foundation: the Open Source Security Foundation; it already raised 10 M$ from 30+ companies.
Next kubecons will occur in Valencia Europe 2022, and Detroit North America October 2022.
A new working group was added to the CNCF : Cartografos which aims to provide tools to help new adopters navigate the (vast!) CNCF landscape.
CNCF has counted 100 000 exams subscribers; and had announced a new security exam and a kubernetes and cloud native associate certification , kcna.
Multi cluster by Kaslien Fields
DNS to balance between clusters ingresses (that then forward to Load balancers) what could go wrong ?
Enter SIG multi cluster, the GW API from SIG Network introduces a concept of multi cluster ingress; you can find a multi cluster services tutorial on github.
Project Updates
The CNCF keeps on adding new projects to its portfolio (now over 130). Some of them were described during the keynotes:
- Cilium (incubation), eBPF-based Networking, Observability, and Security
- Flux (incubation), GitOps tool, integrated in vendor GitOps offering, server side apply for reconciliation: drift detection vs the desired state (git, s3)
- Keda (incubation), Kubernetes Event-driven Autoscaling
- Crossplane (incubation), Provision and manage cloud infrastructure and services using kubectl
- OpenTelemetry, (incubation) now v1.0 with multiple SDKs available (java python go official – ruby python beta) and the collector, it is fully compatible with openmetrics (prometheus compatibility)
- Spiffe / Spire (incubation): Secure Production Identity Framework for Everyone (using JWT and / or X509 certificates), support for Serverless platforms, squarespace is using spiffe / spire
- Linkerd (graduated): the server mesh, just graduated, it was even described as faster than Istio(!?)
Stephen Augustus described SIG (Special Interest Groups : security, release, doc, etc.) and WG (Working Groups – time bounded effort, in comparison to SIG) updates.
An alliance between CNCF and RISC-V was announced.
Kubernetes is still in development – 170 KEPs (enhancement tickets) are opened: the project is definitely not complete!
A Carvel demo was presented: it’s a packaging system on top of kubernetes.
Adoption and sustainability by Constance Caramanolis
Constance reminded us with the fact that most of the CNCF projects don’t really integrate with each other.
Success is adoption and sustainability.
Better integration is possible and is actually happening: from Prometheus metrics format, OpenMetrics was born, then OpenTelemetry encompassed OpenMetrics. But there are still many gaps to fill.
Thinking about the future, we should identify pain points, solve them with new open source projects and identify why some projects end up being abandoned by developers and users.
Creating a Human Centered Developer Experience by Jasmine James
Jasmine James introduced why and how we should create a human centered developer experience, using centralized docs, screen recordings, etc. But also:
- discoverability: tools such as backstage (more on that in the sessions chapter )to help onboard new developers and also
- usability tools such as Helm (re use the same helm charts across environments)
- capability using kubeflow to deploy easily (ML use cases) or using Linkerd that provides a layer between the services and the user code
- stability: one can use litmus to simulate chaos
Building Support For Your Cloud Native Journey
Robert Duffy, from Expedia Group explained how we could make the developer experience better, carefully selecting a common set of tools.

He also explained the need to find allies and how to handle detractors:
- spend time listening to them
- turn rumors and naysayers into tickets
- prove your value with metrics
Sessions
Manage More Clusters with Less Hassle, with Argo CD Application Sets – Jonathan West, Red Hat & Kshama Jain, Independent Contributor
ArgoCD Application sets are a Kubernetes Custom Resource and a controller that works with an existing ArgoCD install.
Such an ApplicationSet describes the applications to create and manage as a single unit, and can also be based off a Git repository.
Introduction to GitOps: Git is the source of truth, desired state stored in files in a Git repository, the GitOps agents will make sure the software is installed and reflects the source of truth.
ArgoCD implements just that, providing a dashboard and support for configuration management tools (ksonnet /jsonnet / helm/ kustomize)
Kshama continued with a demo of ArgoCD.
In a an ArgoCD CR (defined using Yaml for example) you can define the git repo that will be used as the source of truth and the namespace where the software should be deployed
An ArgoCD applicaton set on the other side, allows place holders to be used for the cluster and the url, that a (list) generator will be able to generate the appropriate parameters.
That allows to define within one Custom Resource a list of clusters that will be the targets of deployment of a given git repo.
But you could actually use the clusters already known by ArgoCD and reference them via the cluster generator.
The Git Directory generator can find all the deployments / services in a given git repository sub-directories and deploy them all
The Matrix Generator can combine the output of 2 generators.
Microservices Made Easy! – Donovan Brown & Jessica Deen, Microsoft
Dapr can work with any cloud or edge infrastructure.
Dapr is deployed as a side car that provides components or building blocks to provide integration with a state store (such as a secret provider) , with pub sub brokers, DNS etc. on the application behalf
Donovan did a demo with Dapr wrapping around an existing .NET micro service, receiving requests on a different port than the original app port, sending HTTP traces to zipkin, then forwarding the request to the original service – without touching the existing application code.
Then, he was able to enhance his microservice with pub/sub and he could easily switch from a given pub/sub server to another one just changing a configuration file in Dapr, BUT NOT in the existing service that kept on using Dapr transparently.
Bridge to Kubernetes VS Code extension is an extension to redirect a service (creating and using an envoy pod on the kubernetes cluster) to a laptop running process instead of the existing Kubernetes deployment.
A link was provided to an ebook about Dapr.
Shh, It’s a Secret: Managing Your Secrets in a GitOps Way – Jake Wernette & Josh Kayani, IBM
They described their Kubernetes Journey, how it took them to ArgoCD.
Then, secrets.
In their case, they should be stored in Vault, work with all kubernetes resources and should not need an operator.
The idea is to store in the Git repository a secret.yaml with a placeholder for the secret value (and a special annotation that references the path of the secret in Vault), and have ArgoCD pick it up and transform it (replacing the place holder value with the one from Vault) and finally apply it.
Introducing argocd-vault-plugin (it also supports secret managers from GCP, IBM and AWS, etc.),
They also have a plugin for helm, that basically references the placeholder from the values ArgoCD will pass to the helm command line
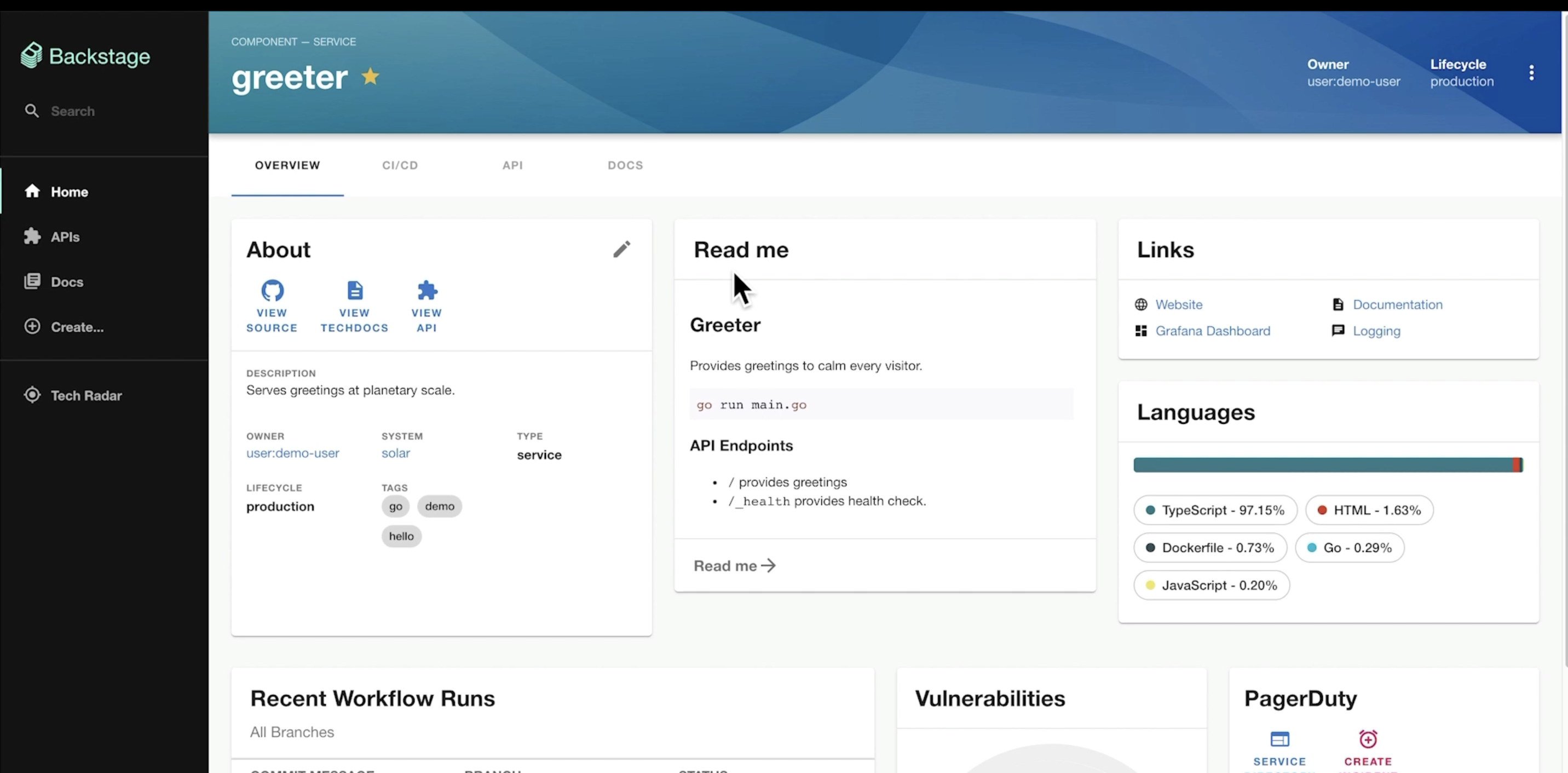
Shifting Spotify Engineering from Spreadsheets to Backstage – Johan Haals & Patrik Oldsberg, Spotify
Backstage is a developer portal: a Web UI that displays all software projects (Git repos) and their status (CI Runs, Issues, Deployments, PagerDuties, Todos, etc.)
Shopify open sourced their own tool to create a developer portal; now they’re in the CNCF (sandbox) and have 50 contrinbutors across several companies.
It’s extendable by plugins. The spotify instance is run on the OSS version.
The project page pull information from different tools into a unified view.
Internally, the components are configured with Yaml.
The catalog references all the components (company projects with a git repo, CI, etc.) registered and used, and provides an API that a frontend can consume to display the projects with all their info.
It’s not only about get read information, but it can also create a new project: Git repo, Wiki page, etc. from a given template.
The catalog can get fed components by automatic discovery of Yaml files (defining components) in a Git repository, or we can manually add new components or have processors discover them.
Improving Dev Experience: How We Built a Cloud Native Dev Stack At Scale – Srinidhi S & Venkatesan Vaidyanathan, Razorpay
They first introduced their production pipelines, using Github Actions and spinaker.
Then they described their pain points developing against different services and setting up a local developement environment.
They then introduced their devstack:
- Telepresence: to swap remote containers with a local process
- Devspace: sync the local code into the the remote pod; to avoid container restarts they set up their image entrypoint to watch the filesystem
- Helmfile: to orchestrate different helm releases, it’s basically a Helm wrapper
- They also used header based routing using Treafik 2.0, where they could specify HTTP Header match to specific services in the cluster
Presenters continued with a demo of their devstack setup.
A Safer Curl | Bash for the Cloud – Carolyn Van Slyck, Microsoft
Carolyn first explains why curl https://domain.com | bash is unsafe (trusting random scripts to run on a laptop or worse on a production machine is not a good idea).
To make it safe, you’d need to download the script, compare its checksum, read it, understand it, and then run it.
Not convenient… Porter, sandboxing at the CNCF, to the rescue (for cloud scenarios only though).
Porter can bundle scripts, but also provide some additionnal information that can be displayed before running the enclosed scripts.(output, required credentials, etc.)
Also, porter runs its bundles from inside a container to not let the bundle retrieve the user environment variables.
Porter also integrates with secrets manager, to allow scripts that require credentials to securely retrieve them from a secret manager instead of from the environment variables.
You can use mixins from inside a bundle to reference Helm, Terraform, etc. executions and their config.
For example, you can have a bundle declare infrastructure with Terraform and use that infrastructure with Helm, passing around Terraform outputs for example.
Correlating Signals in Opentelemetry: Benefits, Stories, and the Road Ahead – Morgan McLean, Splunk & Jaana Dogan, Amazon
In a nutshell, OpenTelemetry provides:
- a collector (usually run as an agent or daemonset)
- SDKs and language instrumentations agents
- a protocol
- a specification and semantic for various use cases
- a community
As of now, OpenTelemetry captures:
- Traces (GA)
- metrics (beta, soon GA)
- logs (alpha soon beta)
Capturing traces, metrics, logs is necessary to understand failures; and failures that happen 10 levels below generate very strange issues at a high level, hence the need to capture all the details.
Morgan went on with an example based on an e commerce application, that was experiencing high latency, and after analyzing the correlation of metrics, traces and logs, he could pinpoint the issue.
The correlation involves application metrics with services – host metrics with services – logs with metrics – logs with services.
Jaana provided 2 other examples where the 3 types of signals were not enough (but helped rule out potential issues) – but debugging and looking at diffs were key to find out the origin of the issue.
Profiling could be the next type of signal to be part of opentelemetry (when metrics and logs are complete).
Also, OpenTelemetry is gaigning support for ebpf instrumentation and network (dns queries, dhcp).
Jaeger: Intro and Deep Dive – Jonah Kowall, Logz.io
A Jaeger deployment needs an agent + a collector (OpenTelemetry can have its agent be used as a collector as well) + a backend (usually a single binary running the UI as well) + backend DB (usually elastic search)
Jonah moved on to describing the feature of the Jaeger Operator that enables the user to deploy Jaeger easily in Kubernetes.
Jaeger Agent can be run as a sidecar container or Daemonset (hence 1 per node for multiple applications)
Traces come in, collector decides whether or not it goes to the backend (simple : a DB, more conplicated, with Kafka)
With remote sampling, you can get more or less data temporarily.
Storage: ElasticSearch and / or Cassandra
ATM (AggregatedTracedMetrics): Jaeger sends traces to the collector that will ingest the traces and generates metrics from them before forwarding them to the back end.
Jaeger is moving from a tracing tool to a full blown monitoring / debugging tool; addition of metrics is just the beginning
YAML Your Cloud! Managing Your Hosted Resources With Kubernetes – Megan O’Keefe & Shabir Mohamed Abdul Samadh, Google
Talk page, Slides, Demo repository
Shabir started reminding the audience with the aarchitecture of a Kubernetes cluster: the API server received the desired state and apply it on one of the worker nodes available to it.
He then went on to explain the Kubernetes Resource Model that includes metadata, desired state and the status
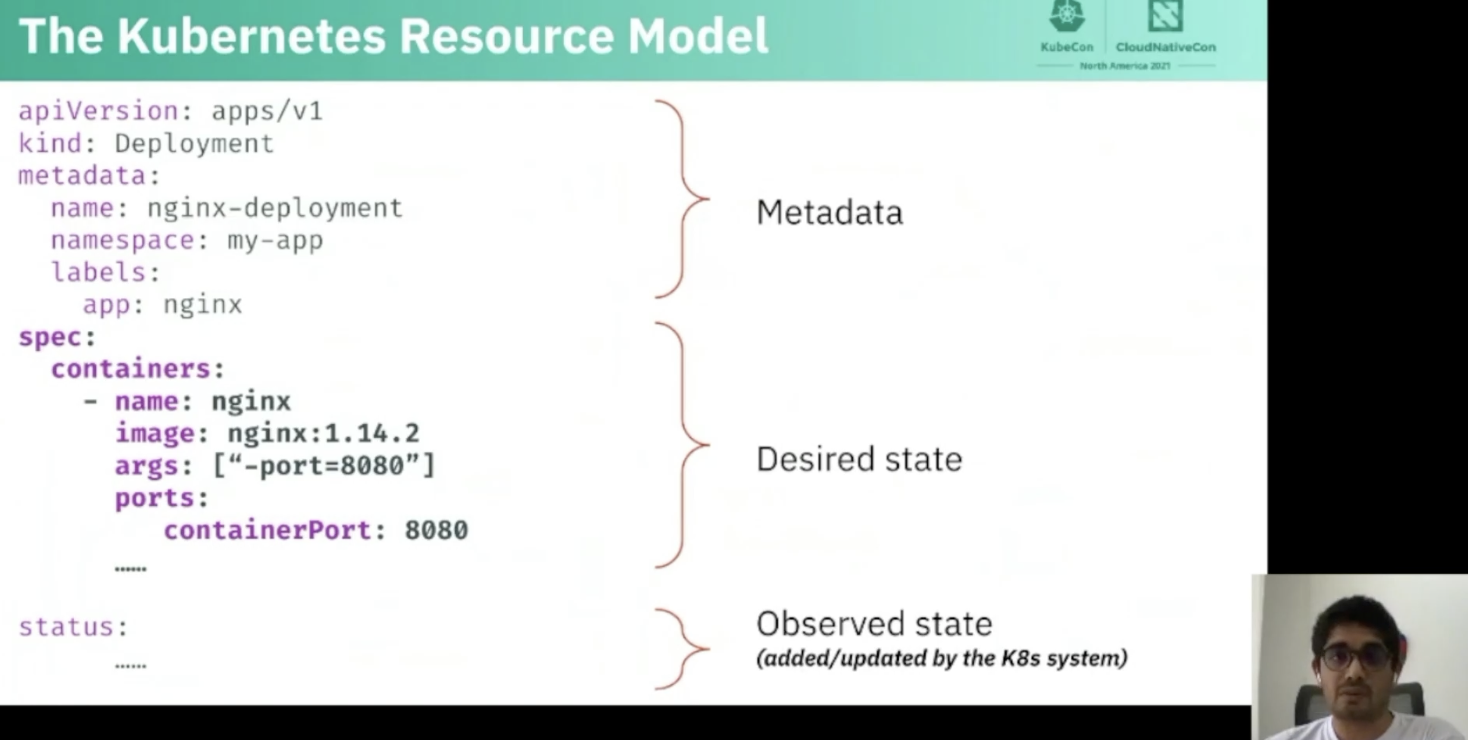
Custom Resource can extend the API with new types of object, such as ArgoCD Application Sets, etc.
When you use a cloud provider, you usually need to use another tool than kubectl and different type of resources as well.
What if.. you could declare your cloud resources from K8s, using the KRM (Kubernetes Resource Model).
Megan continued with some demos; first demo with AWS Controllers for Kubernetes (ACK, it’s open source): defining separate controller per type of resource. Megan demoed a S3 bucket defined from a K8s CRD, and after it was created in AWS (thanks to ACK), she used it from a pod.
Second demo was using Google Cloud, this time using Config Connector for Google Cloud, which is not open source.
What about guardrails? who should be able to create such infrastructure from k8s? RBAC actually already covers those questions, and an OPA GateKeepr can help too enforce rules, using ConstraintTemplates and Constraints.
To be able to control resources across several type of clusters, you can use Crossplane that will assemble multiple resources into a composite unit and explose them as a single resource definition
Shabir demoed the crossplane having an AWS config provider installed in a GCP K8s cluster, that allowed it to create AWS resources, as if it was using the cli with credentials.
Building Prometheus Metrics Support in OpenTelemetry – Alolita Sharma, Amazon
Alolita started her talk with general info about observability and reminded the audience with the architecture of OpenTelemetry
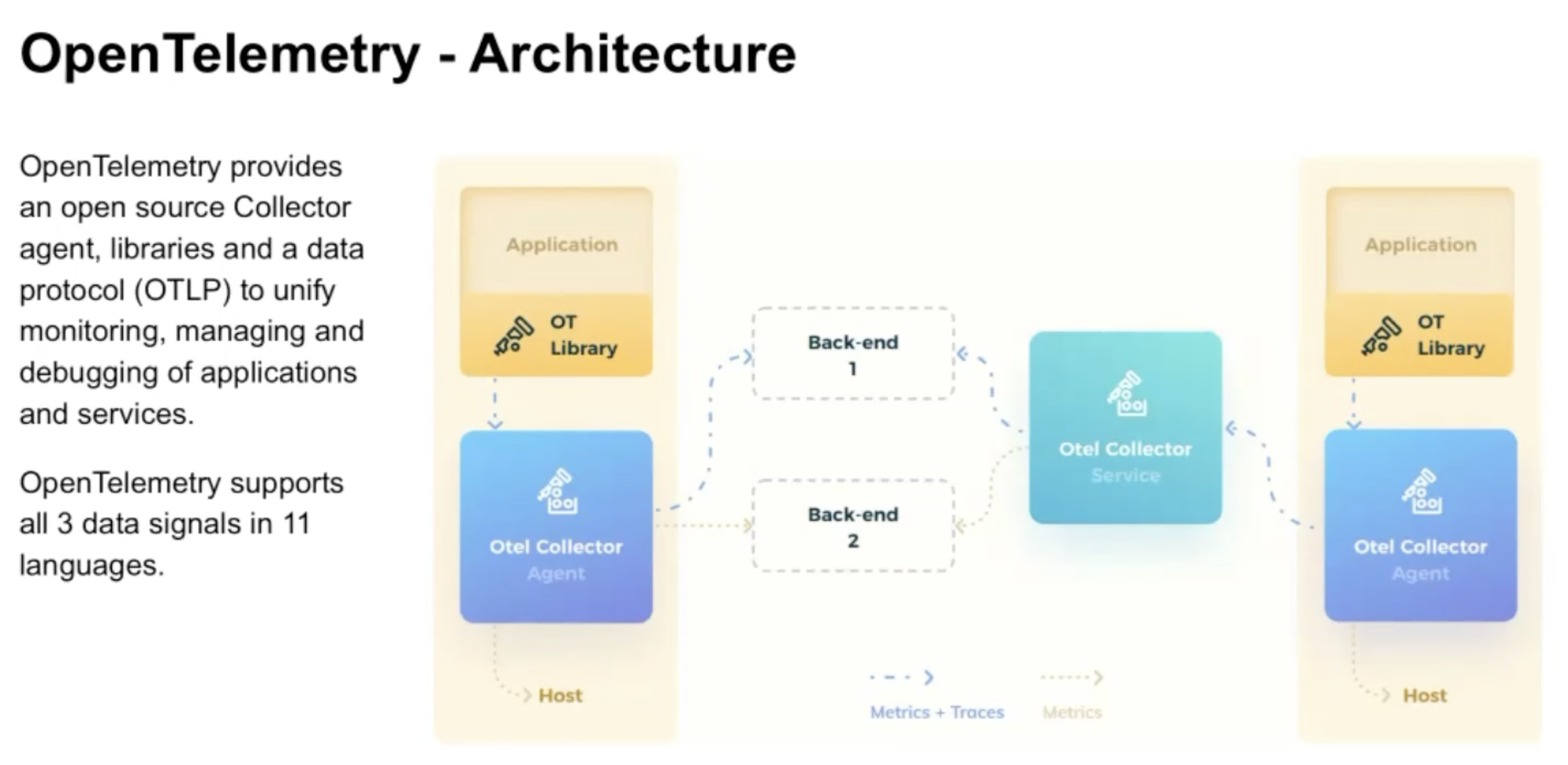
She then explained the efforts engaged to make OpenTelemetry components ingest Prometheus metrics.
You can follow progress of the OpenTelemetry progress on https://opentelemetry.io/status/
Closing remarks: tools and trends
During Kubecon, a lot of interesting tool were described during the keynotes and sessions:
- dnscat: can you believe you can create an encrypted tunnel for Command and Control on top of DNS requests?
- kubejanitor: clear resources, based on annotations cleans up resources after 6 hours (configurable)
- Developer experience:
- Garden, Tilt or Skaffold : I did not hear about them this year
- Dapr, see the session notes, included in a side container to help externalize configuration
- Telepresence: back in a 2.0 version, there was also a nice VSCode extension that reminded me of Telepresence, since it could redirect cluster services to local processes
- DevSpace: a similar tool than Skaffold
- Porter: deploy packages to Kubernetes, safely.
- https://kubestr.io/ : a collection of tools to discover, validate and evaluate your kubernetes storage options.
As a final chapter, I think the following were the most important trends discussed during this Kubecon:
- Observability: OpenTelemetry is progressing, even if it’s still not GA (traces GA, metrics beta, logs alpha) – interesting to see the Jaeger project is aiming at becoming a full blown APM solution.
- GitOps: ArgoCD was very frequently discussed, through a lot of extensions.
- developer environment: I think 2021 is the year of the developer, at Spring One 2021 I had the same sensation, lots of energy on putting the application developer center to the cloud ecosystem
- supply chain security : attacks can occur at every and each level of the software lifecycle, some tools are emerging
- calls for contribution; documentation: many calls to contribution, calls to « maintain the maintainer »